































































Yellow.ai is the next-gen Total Experience Automation platform powered by Dynamic AI agents which empower enterprises to deliver human-like interactions that boost customer satisfaction and amplify employee engagement at scale.
What is Natural Language Processing?
NLP is a field of Artificial Intelligence (AI), primarily focused on working with natural language, that is, human languages like English, Hindi, French, etc. It encompasses both text and voice segments, be it language detection or translation, or performing Speech-to-Text operations.
Some good examples of this would be Virtual Assistants (VA) or Chatbots, automated calling systems, etc.
How is NLP leveraged at Yellow.ai?
Due to the unique position of Yellow.ai being the next-gen Total Experience (TX) automation platform, we have developed solutions catering to both ways of conversations – Text and Voice.
For Voice, the important bits come down to being able to convert the user’s ask to a meaningful transcript that can be used by the platform to answer effectively. Hence, for voice, the 2 key components are:
- Speech to Text (STT) – for converting the spoken language into a text that can be iterated upon.
- Text to Speech (TTS)– to relay back bot message to the user
For Text, we have a variety of tasks that need to be performed. Some of these tasks are:
- Sentiment Analysis – analysing the sentiment of the message whether it’s positive, negative or neutral.
- Language Detection – the language used for the message.
- Intent Matching – checking if the message matches any of the configured intents with a high enough confidence.
- Entity Recognition – detecting any additional information present in the message, like dates, quantity, etc.
- Small Talk Recognition – detecting the common small talk like greetings, etc and providing a way to create delightful experiences.
Aside from the usual conversation based usage of NLP, we are also leveraging the Natural Language Generation capabilities (NLG) for our Document Cognition feature called the Insights engine.
A lot of our customers have unstructured data in the form of documents such as pdf’s, word, text files and ppt and the feature helps fast-track FAQ bot creation by automatically generating QnA pairs from the documents. Document cognition also searches a user query over the entire set of documents and takes a user to the exact page and part of the document that has the answer.
This helps in providing a ready-made solution to construct a knowledge base from existing customer documents and enriching the answers that can be obtained from the bot.
Nuances associated with NLP
Working with NLP on so many fronts has made us encounter a lot of challenges in terms of natural language that has to be thought through carefully. Some of these challenges are:
- Accents play a big role in voice communication. For example, despite speaking English, people may have various accents like American, Indian, British, etc.
As described in the dictionary, accents are a distinctive way of pronouncing a language, especially one associated with a particular country, area, or social class. Thus, care needs to be taken in gathering data and creating models that can handle this. - Combinational languages like Hinglish, etc where the words are from Hindi but written in English script. Since the written language does not match the ideal form, detecting and understanding the message language and intent becomes crucial.
- Understanding different languages and their nuances. Similar to how English has its own grammar and way of writing both formal and informal messages, other languages also have this knowledge base that needs to be understood for communicating with the users.
Similar to accents, there may be other regional nuances in the way people write and communicate. - Lack of data for some languages. This has been a key proponent of the slow NLP growth in a variety of languages as there is not enough research and data to quantise, commercialise and create solutions for a lot of native languages, some of which can just have a population of few thousands speaking or writing it.
- Lack of data for model training. The Machine Learning (ML) field requires considerable data to be able to perform, but for customised models that our customers leverage, there may be an acute shortage of training data for intents, thus a lot of the models may not be able to perform.
This in turn may lead to a high amount of False Positives, i.e., misclassifying the intents for the message during runtime. - As the real world goes, the messages received can have spelling mistakes/shorthand writing. Since the models are trained to infer on well-formed data, if left unchecked, the model prediction may take a hit on these unseen/bogus words.
- For Document Cognition, a particular problem is with structured data. If the document contains structures like tables, graphs, etc, then generating meaningful answers for the questions related to these structures cannot be adequately answered.
An example is, the document containing population and other metrics for different years and we want to find the population for the year 2016. There might be the correct answer, or it can be something else as well.
How Do We Do It?
There are a variety of approaches that we employ to address the various problems that we are working with. Some of these are:
- A variety of models to address the multilingual domains we work in. We have an English only model, and separately, a variety of native multilingual models which are used to understand the message in a variety of languages.
This has helped us in removing the intermediate step of converting the message to English and then predicting the use case. - We have developed a model which can consume documents in a variety of extensions and generate a knowledge base from them by generating the most relevant Questions and Answers.
The model is based on T5 and is a large model. - Models and services are being leveraged for performing the voice pipeline end-to-end, be it Speech to Text (STT) or Text to Speech (TTS).
We have also added support to specify the speed, pauses to be taken, etc for the voice message to seem much more natural and human.
Basic Architecture
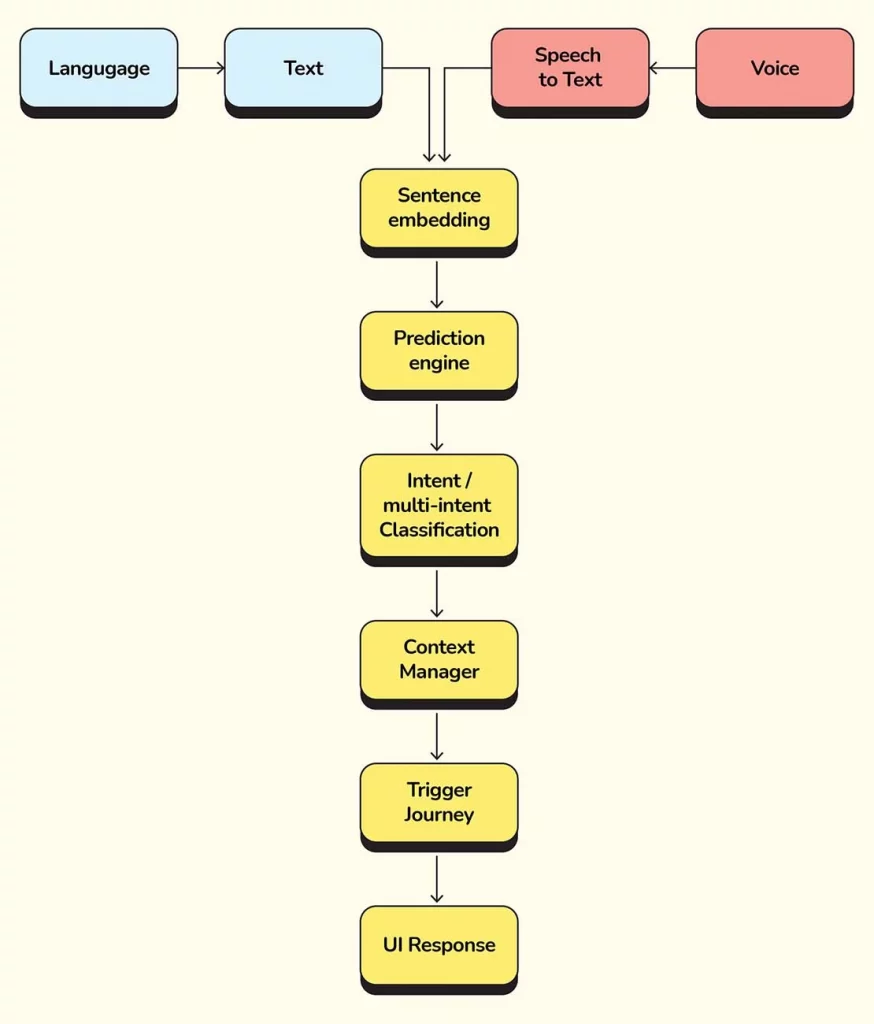
Sentence Embedding: The text needs to be converted to a format which the models can process. Sentence Embedding converts the text to vectors, keeping the meaning encoded.
Context Manager: Going through a use-case, there is a lot of context that needs to be checked for any new message such as, is this a reply to the query from the bot, or if the user is asking for something else entirely.
Context Manager is an in-house development that takes care of all of these nuances.
Trigger Journey: Based on the output from the Context Manager, a decision will be taken on which journey/intent needs to be triggered.
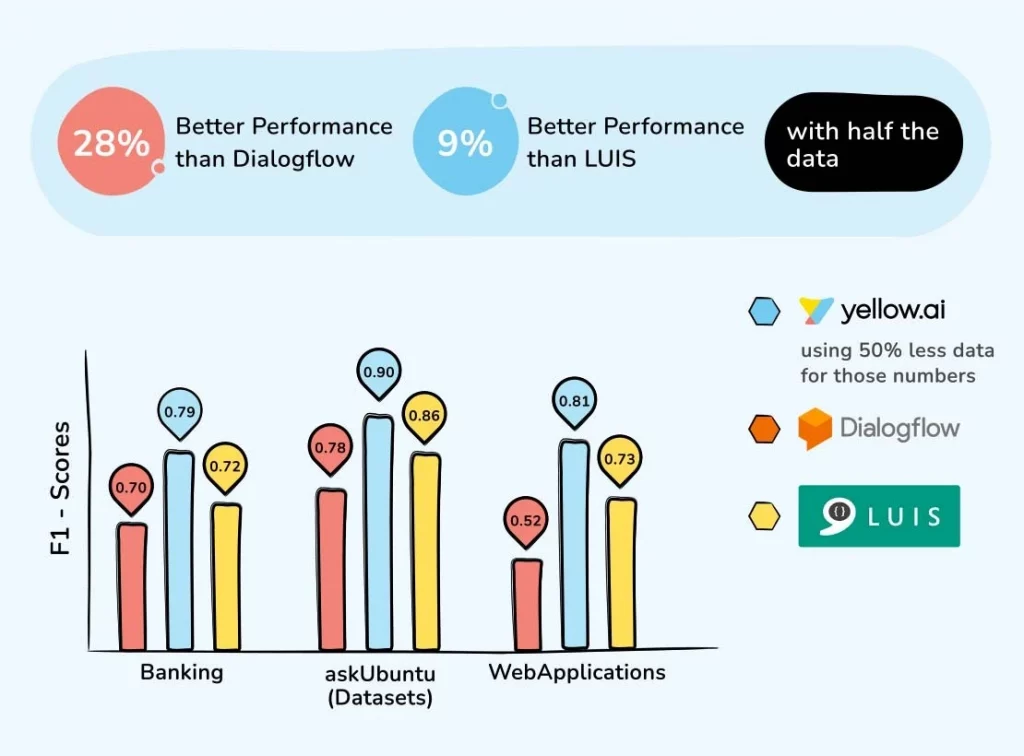
What Do Benchmarks Say?
To gauge how our approach fared against established NLU (natural language understanding) players like Google Dialogflow and Microsoft LUIS, we did a benchmark on some standard datasets for the Intent Detection/Matching task.
Yellow.ai’s approach came out on top even with the handicap of using half the data (50% less data) than the other players.
Co-authored by
Siddharth Goel
With years of experience wearing many hats, Siddharth is currently focusing on building scalable products in the Conversational AI space with impact. Beyond work, he can be found reading books, playing games or trying to deduce why did the chicken cross the road.
Sushanti Kerani
Having dabbled with a multitude of AI domains like computer vision, surveillance intelligence, data science, Sushanti is now focusing on NLP at yellow. She is curious about tech, open-source, startups and wondering if a bot could generate this bio.


