































































Knowledge management is an integrated, systematic approach to identify, manage, and share an enterprise’s information assets, including databases, documents, policies and procedures, to the right people, at the right time. With enterprises sitting on a pile of information that could be gold, knowledge management is still a key challenge for medium to large enterprises.
Did you know? At almost all support centers to date, there are support agents who have to search through a repository of Q&As, knowledge articles to provide responses? Hence, the long wait time!
Self-serve implementations in most large organizations are ineffective for the same reason, as the scope of FAQs is limited and most knowledge actually exists as unstructured data in the form of SOPs, policy documents, reports, ticket dumps, etc. Document Cognition, as a technology, enables users to get instant and accurate answers to their queries from unstructured data using NLP and Machine Comprehension.
Background
We started working on this big and common problem of knowledge sharing around 1.5 years ago with one of our customers that employ approximately 100,000 people representing more than 140 nationalities working in more than 120 countries. They had a staff of around 350 people known as Employee Support Staff (ESS). Their primary responsibility was to search through the HR knowledge base and respond to employee queries based on their country & employee group. Our goal was to build an interface using which the employees could directly search in this vast knowledge base instead of creating a ticket and waiting for ESS to respond. The ESS could also be thus freed up to respond to perform more complex queries faster and spend time on improving the quality of the KBs.
Another use case was where a pharma company that wanted to enable their lab technicians to easily search for SoPs. We also were working to provide automated support to field staff on how to operate certain tools for a service company at the moment. These and several other use cases gave us insights on the ground reality and constraints under which such a solution was supposed to operate, allowing us to build a generic technology that could cater to several different document search needs.
Here’s one of our newest deployments – PIA – deployed for Asian Development Bank
Asian Development bank is an established organisation which operates from 49 regions and larger workforce. The organisation has its own protocol of operations across departments. Every employee had to search for project administration procedures and questions related to it. It’s tough to quickly refer to the documentation and fetch the answers. Procurement portfolio and Financial management department has chosen the NLP based solutions to resolve the employee queries and manage the knowledge base documents. There are more than 450 FAQs and around 50 documents that have to be managed and searched for every user queries.
Adopting Yellow.ai’s insights engines model has helped the organization to resolve queries faster in an efficient way by getting the accurate results. The policy statements of the PPFD Department also come with their own data dictionary and acronyms reference which may be difficult for employees across other departments to recognise. Yellow.ai’s conversational solution handles data dictionaries and synonyms and helps the users with quick access to the solutions. Pia
Enterprise’s Requirement
After speaking with multiple global customers, we boiled down their key requirements of an ideal solution.
Real-time performance on high volume, unstructured data: Should be able to integrate and index content from multiple document sources at a high frequency.
Parsing Multiple Rich media Formats: Should be able to parse different kinds of documents including text, images, tables, etc.
Document Space: Documents can be of varying length, subject matter and word density (Term Frequency and Inverse Dense Frequency).
Response Accuracy: Should provide at least a page-level accuracy. Paragraph level accuracy is desired and exact factual answers would be ideal.
Security, Access control: Should be secure and only search in documents that the user has permissions to access.
Suggested Enterprise-Grade Solution: Document Cognition
Yellow.ai’s Document Cognitions solution can be divided into three steps :
- Mapping: This is the first step, is to find the differences between all versions of documents. Each document is identified with a unique identifier in the system and this identifier is mapped to the unique ID of the document management system.
- Parsing: In order to search and provide the right response efficiently, it’s important that the parser correctly identifies every minute difference between the document. At Yellow.ai, we’ve developed our own parser to perform a meticulous search of documents.
- Training: The parsed documents are further grouped into entities & then passed through a pipeline of multiple proprietary ML models to understand meaning and context.
Query Resolution Flow
A user’s query is first spell-checked & similar words or synonyms are detected. Our custom deep-learning model then identifies and groups these terms as entities and keywords. This processed query is passed through our models that generate the final response for the user. The pictorial representation of this process is below.
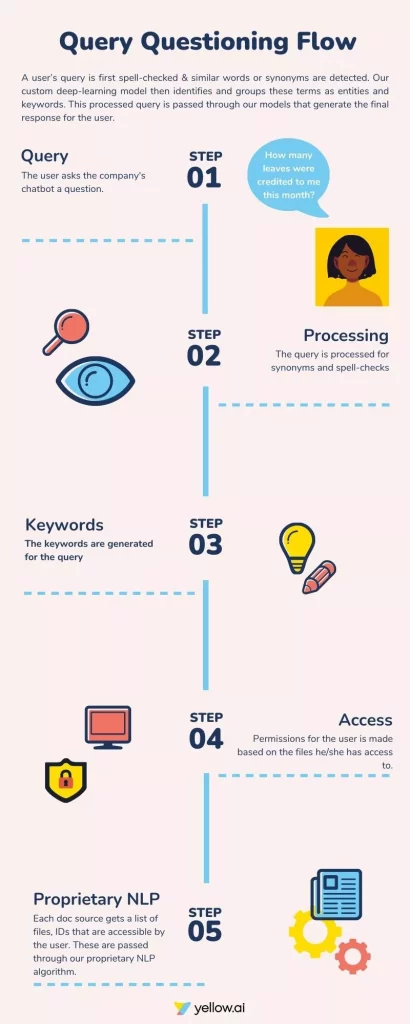
Metadata & Tags
Metadata is a description of a particular document. For example, a documents name, file size, file type, etc. During our initial step of indexing documents, this metadata is also taken into account which can be used by bot developers to add their own tags in the form of key-value pairs. E.g. For HR policy data, each document can be tagged by its country name & would only search in the files tagged to the user’s country.
Performance
So far the model has been tested on hundreds of documents including HR policy data, user manuals, public websites, standard operating procedures and bank policy information and our model is able to successfully surface the right page of the document in ~85% of the cases in the first 5 responses. In the case of factual questions (e.g. Who is Bob Dylan? or Where is Queensland?), the model is able to generate exact answers as well, with very high accuracy. It automatically considers users’ ratings and adapts to the correct values based on user feedback.
Conclusion
Nowadays the importance of knowledge management is clear to many organizations and application leaders search for the main reasons and factors for being successful in knowledge management system design plus implementation through their organizations. With a complete Knowledge Optimization, Discovery and Analytics offerings via the Yellow.ai Conversational AI Platforms, enterprises are not only managing their heaps of knowledge better but are also ensuring their knowledge is reaching the right people at the right time, naturally.



